Sub-clustering and LRP weight plot¶
[1]:
import copy
import numpy as np
import pandas as pd
import scanpy as sc
import os.path as osp
import matplotlib.pyplot as plt
from typing import List, Union, Literal
import STCase
# Define input parameters directly or through interactive widgets
class Args:
def __init__(self, root: str, ds_dir: str, ds_name: str,
h5_name: str, label_col_name: str, n_nei: int, target_types: List[str]=[],
bad_types: List[str]=[], n_clusters: int=-1, alpha: float=0.0, reso: float=None,
init: Union[Literal["one"], Literal["std"], Literal["re_sum"], Literal["sum"]]='one',
gpu: int=0, use_gpu: bool=False, wo_anno: bool=False, region_col_name: str='NULL'):
self.root = root
self.ds_dir = ds_dir
self.ds_name = ds_name
self.h5_name = h5_name
self.label_col_name = label_col_name
self.target_types = target_types
self.bad_types = bad_types
self.n_nei = n_nei
self.n_clusters = n_clusters
self.alpha = alpha
self.reso = reso
self.init = init
self.gpu = gpu
self.use_gpu = use_gpu
self.wo_anno = wo_anno
self.region_col_name = region_col_name
# Usage:
test_args = Args(root='./tests/', ds_dir='datasets/', ds_name='NC_OSCC_s1',
h5_name='s1_nohvg_stringent', target_types=['SCC'],
gpu=1, use_gpu=True, n_nei=6, n_clusters=3, alpha=0.25,
label_col_name='cell_type', region_col_name='cluster_annotations')
Prepare args for sub-clustering¶
[2]:
stcase_args = STCase.prepare(test_args)
Input ST data: AnnData object with n_obs × n_vars = 1131 × 18100 obs: 'pathologist_anno.x', 'sample_id.x', 'cluster_annotations', 'cell_type', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'total_counts_mt', 'log1p_total_counts_mt', 'pct_counts_mt', 'n_genes' var: 'gene_ids', 'feature_types', 'genome', 'mt', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells' uns: 'Cell_neighbors', 'LR_cell_weight', 'LR_celltype_aggregate_weight', 'LR_celltype_edge_num', 'LR_celltype_mean_weight', 'LR_celltype_weight', 'LR_close_gene', 'LR_close_gene_exp', 'LR_gene_complex_exp', 'LR_gene_complex_information', 'LR_pair_information', 'LR_pathway_cell_weight', 'LR_pathway_celltype_count', 'LR_pathway_celltype_edge_num', 'LR_pathway_celltype_mean_weight', 'LR_pathway_celltype_weight', 'cell_type_colors', 'cell_type_list', 'cluster_annotations_colors', 'log1p', 'radius', 'scenic_res', 'spatial' obsm: 'distances', 'spatial'
WARNING: adata.X seems to be already log-transformed.
/home/tid/mambaforge/envs/stcase/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:72: UserWarning: `flavor='seurat_v3'` expects raw count data, but non-integers were found.
318.1384907850702 5932 2.6224580017683468
<Figure size 640x480 with 0 Axes>
Training GNN for sub-clustering¶
[3]:
STCase.train(stcase_args)
>>> Model and Training Details
{ 'root': './tests/', 'ds_dir': 'datasets/', 'ds_name': 'NC_OSCC_s1', 'h5_name': 's1_nohvg_stringent', 'label_col_name': 'cell_type', 'target_types': ['SCC'], 'bad_types': [], 'n_nei': 6, 'n_clusters': 3, 'alpha': 0.25, 'reso': None, 'init': 'one', 'gpu': 1, 'use_gpu': True, 'wo_anno': False, 'region_col_name': 'cluster_annotations', 'time_stamp': '0524_0642', 'raw_path': 'datasets/', 'data_path': 'generated/', 'model_path': 'model/', 'result_path': 'result/', 'embedding_data_path': 'embedding/', 'data_name': 'NC_OSCC_s1', 'device': 1, 'seed': 0, 'lr_cut': 'FULL', 'h': 10, 'n_input': 3000, 'num_epoch': 100, 'learning_rate': 0.001, 'use_norm': False, 'use_whole_gene': False }
>>> For SCC spots
X: (1131, 3000)
>>> Cache exisits: generated/NC_OSCC_s1/pre_cluster_adj_5.pkl
Edges in Adj for SCC: 1422
Edges in Adj' for SCC: 626
#Interaction without edges=555
#Interaction without std=279
#Interaction without edges after replacing=0
Use 1513 LR pairs
>>> STCase sub-clustering...
Initial LR pairs' lambda Parameter containing:
tensor([[1.],
[1.],
[1.],
...,
[1.],
[1.],
[1.]], requires_grad=True)
>>> Epoch: 100, Loss: 0.00046
time: 80.588, l_sp: 0.0005
Min Loss: 0.00046268512960523367
>>> Drawing map
/home/tid/projects/STACCI/STACCI/utils.py:175: FutureWarning: In the future, the default backend for leiden will be igraph instead of leidenalg.
To achieve the future defaults please pass: flavor="igraph" and n_iterations=2. directed must also be False to work with igraph's implementation.
Resolution: 0.19999999999999998
3 clusters in drawing...
>>> Similarity Matrix:
Pred: 0 Pred: 1 Pred: 2
True: core 2.0 41.0 0.0
True: edge 86.0 1.0 25.0
True: nc 24.0 7.0 4.0
True: transitory 28.0 20.0 5.0
>>> Label Mapping: {1: 'core', 0: 'edge', 2: 'transitory'}
>>> ARI: 0.2514609622056457
>>> NMI: 0.2950353059298418
>>> F1-score: 0.4692121042163613
>>> Accuracy: 0.5432098765432098
R[write to console]: __ __
____ ___ _____/ /_ _______/ /_
/ __ `__ \/ ___/ / / / / ___/ __/
/ / / / / / /__/ / /_/ (__ ) /_
/_/ /_/ /_/\___/_/\__,_/____/\__/ version 6.1.1
Type 'citation("mclust")' for citing this R package in publications.
fitting ...
|======================================================================| 100%
>>> Similarity Matrix:
Pred: 0 Pred: 1 Pred: 2
True: core 0.0 42.0 1.0
True: edge 25.0 2.0 85.0
True: nc 4.0 8.0 23.0
True: transitory 5.0 21.0 27.0
>>> Label Mapping: {1: 'core', 2: 'edge', 0: 'transitory'}
>>> ARI: 0.25562096253427424
>>> NMI: 0.2954294274015007
>>> F1-score: 0.4691525868553842
>>> Accuracy: 0.5432098765432098
SCC_alpha=0.25_reso=None_cut=FULL_hvg=3000_nei=6
<Figure size 640x480 with 0 Axes>
Plot results¶
[4]:
t = stcase_args.target_types[0]
print(f">>> For {t.replace('/', 'or')} spots")
>>> For SCC spots
[5]:
args = copy.deepcopy(stcase_args)
data_fold = osp.join(args.raw_path, args.data_name)
adata_h5ad = sc.read_h5ad(osp.join(data_fold, f'{args.h5_name}.h5ad'))
adata_h5ad
[5]:
AnnData object with n_obs × n_vars = 1131 × 18100
obs: 'pathologist_anno.x', 'sample_id.x', 'cluster_annotations', 'cell_type', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'total_counts_mt', 'log1p_total_counts_mt', 'pct_counts_mt', 'n_genes'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells'
uns: 'Cell_neighbors', 'LR_cell_weight', 'LR_celltype_aggregate_weight', 'LR_celltype_edge_num', 'LR_celltype_mean_weight', 'LR_celltype_weight', 'LR_close_gene', 'LR_close_gene_exp', 'LR_gene_complex_exp', 'LR_gene_complex_information', 'LR_pair_information', 'LR_pathway_cell_weight', 'LR_pathway_celltype_count', 'LR_pathway_celltype_edge_num', 'LR_pathway_celltype_mean_weight', 'LR_pathway_celltype_weight', 'cell_type_colors', 'cell_type_list', 'cluster_annotations_colors', 'log1p', 'radius', 'scenic_res', 'spatial'
obsm: 'distances', 'spatial'
[6]:
cell_types = adata_h5ad.obs[args.label_col_name]
print('>>> Cell types:')
print(cell_types)
type_id_list = cell_types[cell_types == t].index.to_list()
print(f">>> {t.replace('/', 'or')} spots index list:")
print(type_id_list)
>>> Cell types:
AAACACCAATAACTGC-1 Lymphocyte Negative Stroma
AAACAGGGTCTATATT-1 SCC
AAACCGTTCGTCCAGG-1 Lymphocyte Negative Stroma
AAACGAGACGGTTGAT-1 SCC
AAACTGCTGGCTCCAA-1 Muscle
...
TTGTGGTAGGAGGGAT-1 Lymphocyte Negative Stroma
TTGTTAGCAAATTCGA-1 Lymphocyte Positive Stroma
TTGTTCAGTGTGCTAC-1 Lymphocyte Positive Stroma
TTGTTGTGTGTCAAGA-1 Lymphocyte Positive Stroma
TTGTTTCCATACAACT-1 Lymphocyte Negative Stroma
Name: cell_type, Length: 1131, dtype: category
Categories (4, object): ['Lymphocyte Negative Stroma', 'Lymphocyte Positive Stroma', 'Muscle', 'SCC']
>>> SCC spots index list:
['AAACAGGGTCTATATT-1', 'AAACGAGACGGTTGAT-1', 'AAATGGCCCGTGCCCT-1', 'AACCCTACTGTCAATA-1', 'AACGATATGTCAACTG-1', 'AACGGCCATCTCCGGT-1', 'AACTCTCAATAGAGCG-1', 'AACTGGGTCCCGACGT-1', 'AAGCTAGATCGAGTAA-1', 'AAGGATCGATCGCTTG-1', 'AAGGTATCCTAATATA-1', 'AAGTTCGGCCAACAGG-1', 'AATCGCCTCAGCGCCA-1', 'AATCTCTACTGTGGTT-1', 'AATCTGCGTTGGGACG-1', 'AATCTGGCTTTCTAGT-1', 'AATTAGCGCTGCAGCG-1', 'AATTCTAGAGTTAGGC-1', 'ACAACAGCATGAGCTA-1', 'ACAATTTGAGCAGTGG-1', 'ACACGAGACTCCTTCT-1', 'ACAGTAATACAACTTG-1', 'ACATAATAAGGCGGTG-1', 'ACATCCTGGTAACTGT-1', 'ACATGGCGCCAAAGTA-1', 'ACCATCCGCCAACTAG-1', 'ACCCAACGCCCGTGGC-1', 'ACCCGGATGACGCATC-1', 'ACCGATGGTAGCATCG-1', 'ACGATCATCTTGTAAA-1', 'ACGTATTACTCCGATC-1', 'ACTATCCAGGGCATGG-1', 'ACTCCCATTCCTAAAG-1', 'ACTCTCTGACTTAGGT-1', 'ACTTATACTTACCCGG-1', 'AGAATAAATCTTCAGG-1', 'AGACCCACCGCTGATC-1', 'AGCACCAGTACTCACG-1', 'AGCTCTTCGTAACCTT-1', 'AGGATCACGCGATCTG-1', 'AGGGTCGATGCGAACT-1', 'AGGGTGCTCTCGAGGG-1', 'AGGGTTCCCTTTGGTT-1', 'AGGTTGAGGCACGCTT-1', 'AGTACGGGCACCTGGC-1', 'AGTCCATTGGCTGATG-1', 'AGTCGACGGTCTCAAG-1', 'AGTCGGTTGCGTGAGA-1', 'AGTGAGACTTCCAGTA-1', 'AGTGATTCAAGCAGGA-1', 'ATAACGGAGTCCAACG-1', 'ATACGCCGGCGAAACC-1', 'ATACTAGCATGACCCT-1', 'ATAGGGATATCCTTGA-1', 'ATAGTTCCACCCACTC-1', 'ATATCAACCTACAGAG-1', 'ATATCGGTAGGGAGAT-1', 'ATATGTCTCCCTAGCC-1', 'ATCACGTGCTAATTAA-1', 'ATCACTTCATCCTCGC-1', 'ATCAGCTCGTCCACTA-1', 'ATCTGGTTAAGACTGT-1', 'ATGGAGCAGGCCGTGA-1', 'ATTAATACTACGCGGG-1', 'CAAGTGTGGTTGCAAA-1', 'CAATAAACCTTGGCCC-1', 'CAATGGATCTCTACCA-1', 'CAATTTCGTATAAGGG-1', 'CACACGCGCTGTCTTA-1', 'CACATGATTCAGCAAC-1', 'CACCCTTGGTGAGACC-1', 'CACGCACAGCGCAGCT-1', 'CACGCGGAACTGTTGC-1', 'CAGCAGCCCGTTCCTT-1', 'CATAACGGACAGTCGT-1', 'CATCTTACACCACCTC-1', 'CATGACTTCGCTGAAT-1', 'CATGATGCACAATTCT-1', 'CATGGTCTAGATACCG-1', 'CCAAGCGTAACTCGTA-1', 'CCACAATGTACGTCTT-1', 'CCAGATAGTTGAGTGA-1', 'CCAGCCTGGACCAATA-1', 'CCATCGCAGTTAAACT-1', 'CCATCTCACCAGTGAA-1', 'CCCAAACATGCTGCTC-1', 'CCCTGACTAACAAATT-1', 'CCGAACACTGGGCCTC-1', 'CCGATCTCAACCTTAT-1', 'CCGCTTACCTCACTCT-1', 'CCGGGCTGCTCCATAC-1', 'CCTAGGCGTAGCGATC-1', 'CCTCCTGAGCCCACAT-1', 'CCTCTAATCTGCCAAG-1', 'CCTGAACGATATATTC-1', 'CCTGAATATTTACATA-1', 'CCTGTGAAACCGTAAC-1', 'CGACGCATCCGTACCT-1', 'CGAGTACTAAAGAGGA-1', 'CGAGTTTATCGGACTG-1', 'CGCACATGTCCACTAC-1', 'CGCACGTGCGCTATCA-1', 'CGCCACAGGTCGCGAT-1', 'CGCCGCCCATGCCTGT-1', 'CGCGGGAATTAGGCAG-1', 'CGCTAGAGACCGCTGC-1', 'CGCTTTCTTGCATTCG-1', 'CGGGTGTACCCATTTA-1', 'CGGTCAAGTGGGAACC-1', 'CGTACCTGATAGGCCT-1', 'CGTCGGATAGTGTTGA-1', 'CTACCCTAAGGTCATA-1', 'CTCATTTGATGGGCGG-1', 'CTCGGTACCACTGCTC-1', 'CTCTCACAATCGATGA-1', 'CTGGCGCACAGGTCTG-1', 'CTGGGATAAATAATGG-1', 'CTGTTCACTGCCTGTG-1', 'CTTGAGTTAGGGTAAT-1', 'CTTGTCAACATTCGAG-1', 'CTTGTTGCTGAGTCAA-1', 'GAAAGAACAGCGTTAT-1', 'GAACGTCTCATGGTCG-1', 'GAAGTCTCCCTAGCGA-1', 'GAATGTTGGGTAATCT-1', 'GACAACGACCATTGAA-1', 'GACTCACCCACGTGAG-1', 'GAGCTAAGGGCATATC-1', 'GATAACTCGCACTGTG-1', 'GATATGAGACACTAAC-1', 'GCAACACACTAGAACT-1', 'GCAGACCCAGCACGTA-1', 'GCAGATTAGGGATATC-1', 'GCCACAATTTAAGGAC-1', 'GCCCGTAATACCTTCT-1', 'GCCTCATCTGGAAATA-1', 'GCGACATGTAAACATC-1', 'GCGCAAGAGCGCGCTG-1', 'GCGTGGTACTGGGTTA-1', 'GCTAAGTAGTTTCTCT-1', 'GCTAGACCGTCTACTG-1', 'GCTAGTAGAGCTTGTA-1', 'GCTCGCTCATGTCCAA-1', 'GCTGTATTACTGGCCC-1', 'GCTGTTGCTACCGAAC-1', 'GCTTATGAAGCAGGAA-1', 'GGACCAACAGGATAAC-1', 'GGAGCACCAAGAACTA-1', 'GGATGTCCTTACCGCA-1', 'GGATTTCACTTCTATA-1', 'GGCAGAGAGATCGGGA-1', 'GGGCCGGCCGAAGTAC-1', 'GGTCGGCCAGGAGCTT-1', 'GGTGAAGTACAGGGAT-1', 'GGTTACCACCCTCGGG-1', 'GGTTCTACTCGTCTGA-1', 'GGTTTACAATCTCAAT-1', 'GGTTTCAATCGGTCAG-1', 'GTAAGTAACAGTCTGG-1', 'GTACACTTACCTGAAG-1', 'GTACAGAGGCAAGGGT-1', 'GTACTGGAGTTAGACC-1', 'GTAGCTTCCTCTTGTT-1', 'GTATGTGGGTCTAGTT-1', 'GTCAAGCGGACTCGGG-1', 'GTCATTAGAGCGAACG-1', 'GTCCCAACGTAAAGTA-1', 'GTCGTACCTACGATTG-1', 'GTGACCGCACACTACG-1', 'GTGAGGACACTTAAGG-1', 'GTGCCCGTTCGGATTC-1', 'GTGCGACAGGGAGTGT-1', 'GTGTACCTTGGCTACG-1', 'GTGTTACTATGCGTCC-1', 'GTTGGATTGAGAACAC-1', 'GTTTGGCCCAAGTTAT-1', 'GTTTGGGCTTGTGAGC-1', 'TAAGTAACATCTTGAC-1', 'TAATAGTGACGACCAG-1', 'TACATCCCTATCCCTG-1', 'TACTTGTTAGTAGTCC-1', 'TAGACGCCCGTACCGG-1', 'TAGCCGGCGGTCAGCG-1', 'TAGGGAGCTTGGGATG-1', 'TATAGATGGTCGCAGT-1', 'TATATCCCTGGGAGGA-1', 'TATCAGTGGCGTAGTC-1', 'TATGGTTAGTGGGAGA-1', 'TATGTCTCATTGTGCC-1', 'TATTACCATCCTGCTT-1', 'TCAACATCGACCGAGA-1', 'TCACGTGCCCGATTCA-1', 'TCAGCAAATGCATCTC-1', 'TCATTTAAGTCTCCGA-1', 'TCCCGTCAGTCCCGCA-1', 'TCCGCTTATCCCATTA-1', 'TCCTCGGGCTGGGCTT-1', 'TCGCCGAAGTTGCGTC-1', 'TCGGACGCCCAGCCCA-1', 'TCGGAGTACATGAGTA-1', 'TCGTAAGACGACATTG-1', 'TCTACCGTCCACAAGC-1', 'TCTATCGGTCGCAACA-1', 'TCTGAATTCCGTACAA-1', 'TCTGCCAGAAACTGCA-1', 'TCTGGGAACCTTTGAA-1', 'TCTTAGAGCTCCAATT-1', 'TCTTAGAGTGAACTCT-1', 'TCTTGGTAACACCAAA-1', 'TGACATCGAGCGGACC-1', 'TGACGATGCACTAGAA-1', 'TGAGTGGTCCGTGACG-1', 'TGCAGGATCGGCAAAG-1', 'TGCATATGTCTGTCAC-1', 'TGCATGTGGTAATCTA-1', 'TGCGAATATGGGATTT-1', 'TGCGGAGTAAAGGTGC-1', 'TGCGTTTGTTGACACT-1', 'TGCTGTTGAAGAACTC-1', 'TGGAAGGATAAAGATG-1', 'TGTAGGAGAAATTTCC-1', 'TGTATAACAGATCCTG-1', 'TGTGGCAAAGCGTATG-1', 'TTACATGCCACAACTA-1', 'TTACGGATGGTTCGAG-1', 'TTACTCCGGCCGGGAA-1', 'TTAGCTGATTTGCCGT-1', 'TTATATTTGGCAATCC-1', 'TTATCTGTATCATAAC-1', 'TTATGATCTTAACGAA-1', 'TTCAATACTCTGAATC-1', 'TTCCAGACGAGATTTA-1', 'TTCCCGGCGCCAATAG-1', 'TTCTAACCGAAGCTTA-1', 'TTCTGCGGGTTAGCGG-1', 'TTCTTGAGCCGCGCTA-1', 'TTGAATTCACGTGAGG-1', 'TTGACCATGTTCTCCG-1', 'TTGACGCTCCATGAGC-1', 'TTGCACGGAGCAGCAC-1', 'TTGCTCCCATACCGGA-1', 'TTGTAAGGCCAGTTGG-1', 'TTGTCGTTCAGTTACC-1']
[7]:
gene_tag = f"hvg={'FULL' if args.use_whole_gene else args.n_input}"
method = f"{t.replace('/', 'or')}_alpha={args.alpha}_reso={args.reso}_" + \
f"cut={args.lr_cut}_{gene_tag}_nei={args.n_nei}"
outdir = osp.join('results/', args.data_name, args.time_stamp, method)
f = open(osp.join(outdir, f"mclust_fixed_n={args.n_clusters}_{t.replace('/', 'or')}_types.txt")) # Use mclust result
line = f.readline() # drop the first line
cell_cluster_type_list = []
while line:
tmp = line.split('\t')
cell_cluster_type = str(tmp[1].replace('\n', '')).strip()
cell_cluster_type_list.append(f'{t}_{cell_cluster_type}')
line = f.readline()
f.close()
print(f">>> Predicted {t.replace('/', 'or')} spots sub-cluster label list:")
print(cell_cluster_type_list)
>>> Predicted SCC spots sub-cluster label list:
['SCC_0', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_0', 'SCC_2', 'SCC_0', 'SCC_1', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_0', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_0', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_0', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_0', 'SCC_1', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_1', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_0', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_1', 'SCC_0', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_0', 'SCC_2', 'SCC_2', 'SCC_0', 'SCC_2', 'SCC_1', 'SCC_2', 'SCC_2', 'SCC_1', 'SCC_1', 'SCC_1']
[8]:
adata_h5ad.obs[args.label_col_name] = adata_h5ad.obs.apply(lambda row: cell_cluster_type_list[type_id_list.index(row.name)] if row[args.label_col_name] == t else row[args.label_col_name], axis=1)
print('>>> Sub-clustered cell types:')
adata_h5ad.obs[args.label_col_name]
>>> Sub-clustered cell types:
[8]:
AAACACCAATAACTGC-1 Lymphocyte Negative Stroma
AAACAGGGTCTATATT-1 SCC_0
AAACCGTTCGTCCAGG-1 Lymphocyte Negative Stroma
AAACGAGACGGTTGAT-1 SCC_2
AAACTGCTGGCTCCAA-1 Muscle
...
TTGTGGTAGGAGGGAT-1 Lymphocyte Negative Stroma
TTGTTAGCAAATTCGA-1 Lymphocyte Positive Stroma
TTGTTCAGTGTGCTAC-1 Lymphocyte Positive Stroma
TTGTTGTGTGTCAAGA-1 Lymphocyte Positive Stroma
TTGTTTCCATACAACT-1 Lymphocyte Negative Stroma
Name: cell_type, Length: 1131, dtype: object
[9]:
# Plot Sub-clustering
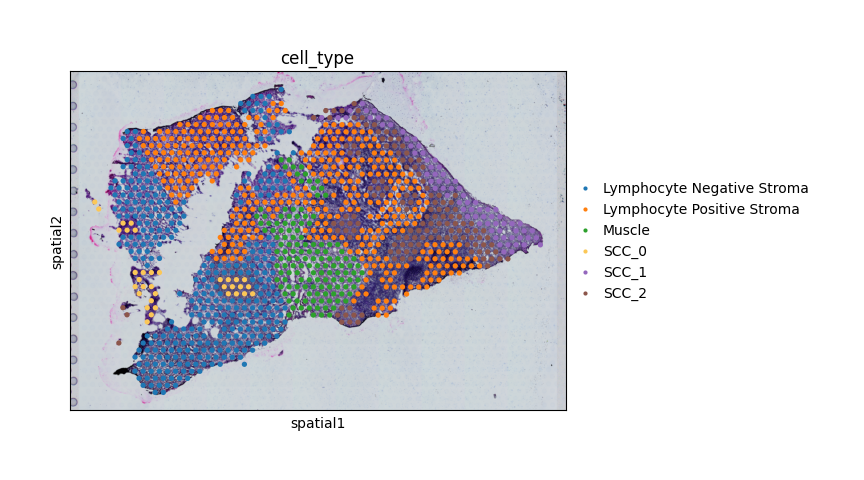
adata_h5ad.uns[f'{args.label_col_name}_colors'] = ['#1f77b4', '#ff7f0e', '#2ca02c', '#FBC757', '#9467bd', '#8c564b']
sc.pl.spatial(adata_h5ad, color=args.label_col_name)
[10]:
# Plot LRP weight
result_path = osp.join(
args.result_path, args.data_name, args.time_stamp, method
)
df = pd.read_csv(osp.join(result_path, f'lr_weight.csv'))
print(f">>> Found inflection point: {STCase.tl.Inflection_point_finding(df, vis=True)}")

>>> Found inflection point: 411
[ ]: